Vossian Antonomasia

Automatic extraction of Vossian antonomasia from large newspaper corpora.
(Shout-out to Gerardus Vossius, 1577–1649.)
statistics
temporal distribution
We plot some temporal distributions:
echo "year articles found true prec"
for year in $(seq 1987 2007); do
echo $year \
$(grep ^$year articles.tsv | cut -d' ' -f2) \
$(../org.py -f year README.org | grep ${year} | wc -l) \
$(../org.py -f year,classification,status README.org | grep ${year} | awk -F$'\t' '{if ($3 == "D" || $2 == "True") print;}' | wc -l)
done
| year | articles | found | true | prec | ppm |
|---|---|---|---|---|---|
| 1987 | 106104 | 207 | 103 | 49.8 | 0.97 |
| 1988 | 104541 | 223 | 99 | 44.4 | 0.95 |
| 1989 | 102818 | 227 | 109 | 48.0 | 1.06 |
| 1990 | 98812 | 232 | 111 | 47.8 | 1.12 |
| 1991 | 85135 | 217 | 107 | 49.3 | 1.26 |
| 1992 | 82685 | 230 | 115 | 50.0 | 1.39 |
| 1993 | 79200 | 239 | 124 | 51.9 | 1.57 |
| 1994 | 74925 | 252 | 129 | 51.2 | 1.72 |
| 1995 | 85392 | 249 | 134 | 53.8 | 1.57 |
| 1996 | 79077 | 306 | 155 | 50.7 | 1.96 |
| 1997 | 85396 | 278 | 143 | 51.4 | 1.67 |
| 1998 | 89163 | 338 | 191 | 56.5 | 2.14 |
| 1999 | 91074 | 320 | 150 | 46.9 | 1.65 |
| 2000 | 94258 | 362 | 188 | 51.9 | 1.99 |
| 2001 | 96282 | 319 | 165 | 51.7 | 1.71 |
| 2002 | 97258 | 389 | 191 | 49.1 | 1.96 |
| 2003 | 94235 | 357 | 186 | 52.1 | 1.97 |
| 2004 | 91362 | 339 | 163 | 48.1 | 1.78 |
| 2005 | 90004 | 396 | 179 | 45.2 | 1.99 |
| 2006 | 87052 | 411 | 187 | 45.5 | 2.15 |
| 2007 | 39953 | 180 | 85 | 47.2 | 2.13 |
| sum | 1854726 | 6071 | 3014 | 49.6 | 34.71 |
| mean | 88320 | 289 | 144 | 49.8 | 1.63 |
: The temporal distribution of the number of found and true candidates.
reset
set datafile separator "\t"
set xlabel "year"
set ylabel "frequency"
set grid linetype 1 linecolor 0
set yrange [0:*]
set y2range [0:100]
set y2label 'precision'
set y2tics
set key top left
set style fill solid 1
set term svg enhanced size 800,600 dynamic fname "Palatino Linotype, Book Antiqua, Palatino, FreeSerif, serif" fsize 16
#set out "nyt_vossantos_over_time.svg"
plot data using 1:3 with linespoints pt 7 lc "red" title 'candidates',\
data using 1:4 with linespoints pt 7 lc "green" title 'Vossantos',\
data using 1:5 with lines lc "blue" title 'precision' axes x1y2
# data using 1:2 with linespoints pt 7 axes x1y2 title 'cand',\
# data using 1:3 with linespoints pt 7 axes x1y2 title 'wd',\
set term png enhanced size 800,600 font "Arial,16" lw 2
set out "nyt_vossantos_over_time.png"
replot
set key bottom left
set term pdf enhanced fontscale .7 lw 2
set out "nyt_vossantos_over_time.pdf"
replot
# ---- relative values
set key top left
set term svg enhanced size 800,600 dynamic fname "Palatino Linotype, Book Antiqua, Palatino, FreeSerif, serif" fsize 16
set out "nyt_vossantos_over_time_rel.svg"
set ylabel "frequency (per mille)"
set format y "%2.1f"
plot data using 1:($3/$2*1000) with linespoints pt 7 lc "red" title 'candidates',\
data using 1:($4/$2*1000) with linespoints pt 7 lc "green" title 'Vossantos',\
data using 1:5 with lines lc "blue" title 'precision' axes x1y2
set term png enhanced size 800,600 font "Arial,16" lw 2
set out "nyt_vossantos_over_time_rel.png"
replot
set term pdf enhanced lw 2
set out "nyt_vossantos_over_time_rel.pdf"
replot
Absolute frequency: 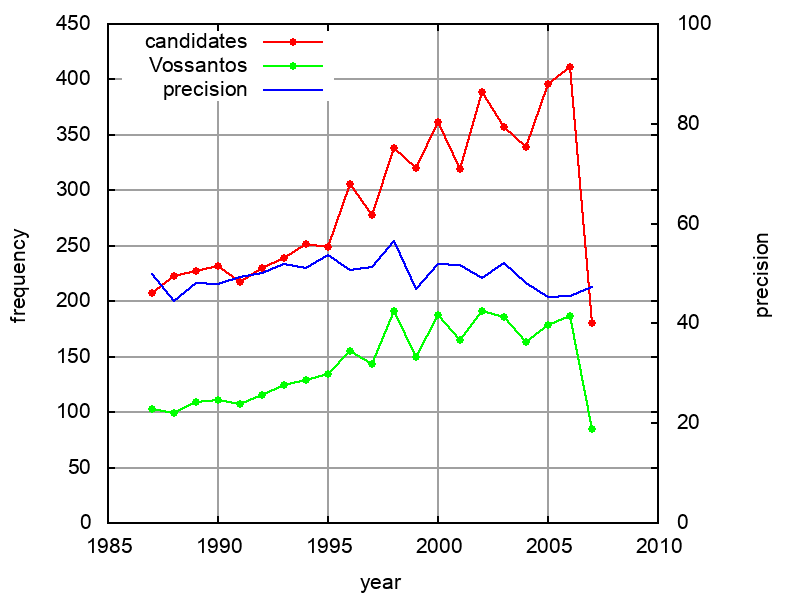
Relative frequency: 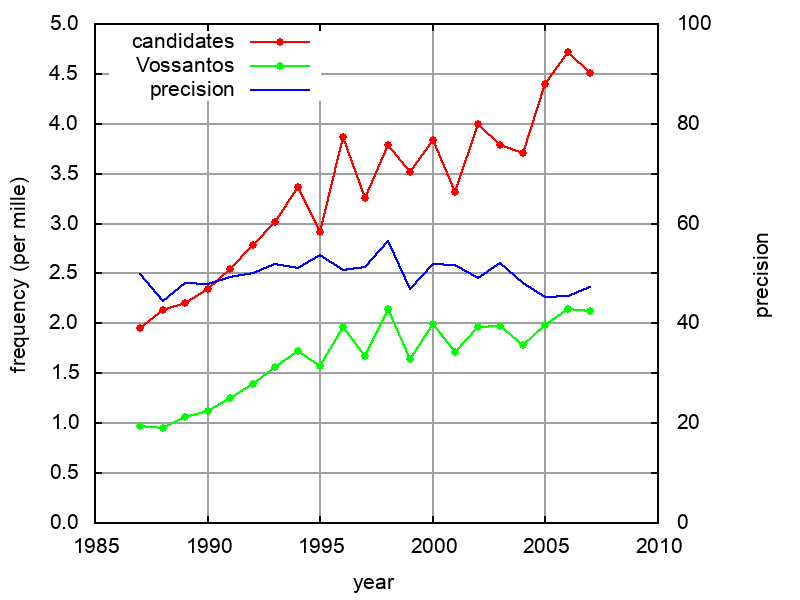
sources
most frequent
The most frequent sources are:
../org.py -T -f sourceUrl README.org | sort | uniq -c | sort -nr | head -n40
| count | source |
|---|---|
| 72 | Michael Jordan |
| 62 | Rodney Dangerfield |
| 40 | Johnny Appleseed |
| 36 | Elvis Presley |
| 36 | Babe Ruth |
| 25 | Michelangelo |
| 25 | Donald Trump |
| 23 | Pablo Picasso |
| 23 | Bill Gates |
| 23 | Madonna |
| 21 | Jackie Robinson |
| 20 | P. T. Barnum |
| 20 | Tiger Woods |
| 19 | Martha Stewart |
| 17 | William Shakespeare |
| 17 | Wolfgang Amadeus Mozart |
| 17 | Cinderella |
| 16 | Henry Ford |
| 16 | John Wayne |
| 15 | Napoleon |
| 14 | Leonardo da Vinci |
| 14 | Greta Garbo |
| 14 | Rosa Parks |
| 14 | Adolf Hitler |
| 14 | Mother Teresa |
| 14 | Ralph Nader |
| 13 | Cal Ripken |
| 12 | Willie Horton |
| 12 | Leo Tolstoy |
| 12 | Rembrandt |
| 12 | Oprah Winfrey |
| 12 | Susan Lucci |
| 11 | Walt Disney |
| 11 | Mike Tyson |
| 10 | Albert Einstein |
| 10 | Thomas Edison |
| 10 | Paul Revere |
| 10 | Julia Child |
| 10 | Cassandra |
| 9 | James Dean |
temporal distribution
for year in $(seq 1987 2007); do
echo -n $year
for s in "Michael_Jordan" "Rodney_Dangerfield" "Johnny_Appleseed"; do
s=$(echo $s| sed "s/_/ /g")
c=$(../org.py -T -f year,sourceLabel README.org | grep ^$year | awk -F'\t' '{print $2}' | grep "^$s$" | wc -l)
echo -n "\t$c"
done
echo
done
| year | Michael Jordan | Rodney Dangerfield | Johnny Appleseed |
|---|---|---|---|
| 1987 | 0 | 0 | 2 |
| 1988 | 0 | 0 | 1 |
| 1989 | 1 | 1 | 1 |
| 1990 | 3 | 2 | 1 |
| 1991 | 4 | 1 | 1 |
| 1992 | 2 | 4 | 1 |
| 1993 | 3 | 4 | 2 |
| 1994 | 3 | 0 | 0 |
| 1995 | 0 | 1 | 3 |
| 1996 | 4 | 8 | 3 |
| 1997 | 1 | 3 | 1 |
| 1998 | 6 | 7 | 2 |
| 1999 | 11 | 2 | 3 |
| 2000 | 11 | 6 | 1 |
| 2001 | 7 | 5 | 1 |
| 2002 | 5 | 2 | 3 |
| 2003 | 2 | 1 | 3 |
| 2004 | 0 | 1 | 3 |
| 2005 | 2 | 8 | 4 |
| 2006 | 4 | 5 | 3 |
| 2007 | 3 | 1 | 1 |
reset
set datafile separator "\t"
set xlabel "year"
set ylabel "frequency"
set grid linetype 1 linecolor 0
set yrange [0:*]
set key top left
set style fill solid 1
set term svg enhanced size 800,600 dynamic font "Palatino Linotype, 16"
#set out "nyt_sources_over_time.svg"
plot data using 1:2 with linespoints pt 7 lw 2 title 'Michael Jordan',\
data using 1:3 with linespoints pt 7 title 'Rodney Dangerfield',\
data using 1:4 with linespoints pt 7 title 'Johnny Appleseed'
set term png enhanced size 800,600 font "Arial,16" lw 2
set out "nyt_sources_over_time.png"
replot
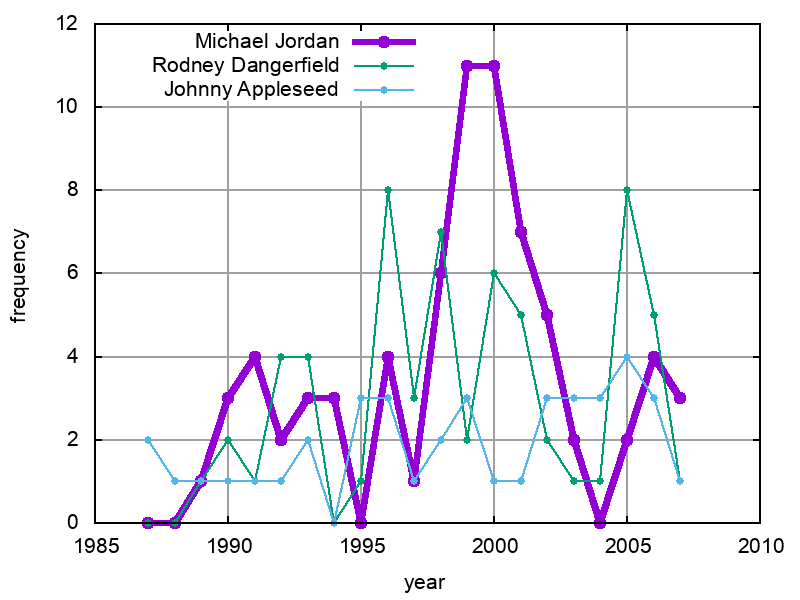
categories
online
Extract the categories for the articles:
export PYTHONIOENCODING=utf-8
for year in $(seq 1987 2007); do
../nyt.py --category ../nyt_corpus_${year}.tar.gz \
| sed -e "s/^nyt_corpus_//" -e "s/\.har\//\//" -e "s/\.xml\t/\t/" \
| sort >> nyt_categories.tsv
done
Compute frequency distribution over all articles:
cut -d$'\t' -f2 nyt_categories.tsv | sort -S1G | uniq -c \
| sed -e "s/^ *//" -e "s/ /\t/" | awk -F'\t' '{print $2"\t"$1}' \
> nyt_categories_distrib.tsv
Check the number of and the top categories:
echo articles $(wc -l < nyt_categories.tsv)
echo categories $(wc -l < nyt_categories_distrib.tsv)
echo ""
sort -nrk2 nyt_categories_distrib.tsv | head
| articles | 1854726 |
|---|---|
| categories | 1580 |
| Business | 291982 |
| Sports | 160888 |
| Opinion | 134428 |
| U.S. | 89389 |
| Arts | 88460 |
| World | 79786 |
| Style | 65071 |
| Obituaries | 19430 |
| Magazine | 11464 |
| Travel | 10440 |
Collect the categories of the articles
echo "vossantos" $(../org.py -T README.org | wc -l) articles $(wc -l < nyt_categories.tsv)
../org.py -T -f fId README.org | join nyt_categories.tsv - | sed "s/ /\t/" | awk -F'\t' '{print $2}' \
| sort | uniq -c \
| sed -e "s/^ *//" -e "s/ /\t/" | awk -F'\t' '{print $2"\t"$1}' \
| join -t$'\t' -o1.2,1.1,2.2 - nyt_categories_distrib.tsv \
| sort -nr | head -n20
| vossantos | 3014 | category | articles | 1854726 |
|---|---|---|---|---|
| 364 | 12.1% | Arts | 88460 | 4.8% |
| 362 | 12.0% | Sports | 160888 | 8.7% |
| 327 | 10.8% | New York and Region | 221897 | 12.0% |
| 287 | 9.5% | Arts; Books | 35475 | 1.9% |
| 186 | 6.2% | Movies; Arts | 27759 | 1.5% |
| 125 | 4.1% | Business | 291982 | 15.7% |
| 122 | 4.0% | Opinion | 134428 | 7.2% |
| 110 | 3.6% | U.S. | 89389 | 4.8% |
| 104 | 3.5% | Magazine | 11464 | 0.6% |
| 76 | 2.5% | Arts; Theater | 13283 | 0.7% |
| 70 | 2.3% | Style | 65071 | 3.5% |
| 52 | 1.7% | World | 79786 | 4.3% |
| 49 | 1.6% | Home and Garden; Style | 13978 | 0.8% |
| 37 | 1.2% | 42157 | 2.3% | |
| 36 | 1.2% | Travel | 10440 | 0.6% |
| 35 | 1.2% | Technology; Business | 23283 | 1.3% |
| 30 | 1.0% | Week in Review | 17107 | 0.9% |
| 29 | 1.0% | Home and Garden | 5546 | 0.3% |
| 18 | 0.6% | Style; Magazine | 1519 | 0.1% |
| 18 | 0.6% | Front Page; U.S. | 11425 | 0.6% |
desks
Extract the desks for the articles:
export PYTHONIOENCODING=utf-8
for year in $(seq 1987 2007); do
../nyt.py --desk ../nyt_corpus_${year}.tar.gz \
| sed -e "s/^nyt_corpus_//" -e "s/\.har\//\//" -e "s/\.xml\t/\t/" \
| sort >> nyt_desks.tsv
done
Compute frequency distribution over all articles:
cut -d$'\t' -f2 nyt_desks.tsv | sort -S1G | uniq -c \
| sed -e "s/^ *//" -e "s/ /\t/" | awk -F'\t' '{print $2"\t"$1}' \
> nyt_desks_distrib.tsv
Check the number of and the top categories:
echo articles $(wc -l < nyt_desks.tsv)
echo categories $(wc -l < nyt_desks_distrib.tsv)
echo ""
sort -t$'\t' -nrk2 nyt_desks_distrib.tsv | head
| articles | 1854727 |
|---|---|
| categories | 398 |
| Metropolitan Desk | 237896 |
| Financial Desk | 206958 |
| Sports Desk | 174823 |
| National Desk | 143489 |
| Editorial Desk | 131762 |
| Foreign Desk | 129732 |
| Classified | 129660 |
| Business/Financial Desk | 112951 |
| Society Desk | 44032 |
| Cultural Desk | 40342 |
Collect the desks of the articles
echo "vossantos" $(../org.py -T README.org | wc -l) articles $(wc -l < nyt_desks.tsv)
../org.py -T -f fid README.org | join nyt_desks.tsv - | sed "s/ /\t/" | awk -F'\t' '{print $2}' \
| sort | uniq -c \
| sed -e "s/^ *//" -e "s/ /\t/" | awk -F'\t' '{print $2"\t"$1}' \
| join -t$'\t' -o1.2,1.1,2.2 - nyt_desks_distrib.tsv \
| sort -nr | head -n20
| vossantos | 3014 | desk | articles | 1854726 |
|---|---|---|---|---|
| 381 | 12.6% | Sports Desk | 174823 | 9.4% |
| 222 | 7.4% | Metropolitan Desk | 237896 | 12.8% |
| 220 | 7.3% | Book Review Desk | 32737 | 1.8% |
| 180 | 6.0% | National Desk | 143489 | 7.7% |
| 171 | 5.7% | The Arts/Cultural Desk | 38136 | 2.1% |
| 169 | 5.6% | Arts and Leisure Desk | 27765 | 1.5% |
| 135 | 4.5% | Magazine Desk | 25433 | 1.4% |
| 125 | 4.1% | Editorial Desk | 131762 | 7.1% |
| 117 | 3.9% | Cultural Desk | 40342 | 2.2% |
| 99 | 3.3% | Movies, Performing Arts/Weekend Desk | 13929 | 0.8% |
| 96 | 3.2% | Business/Financial Desk | 112951 | 6.1% |
| 90 | 3.0% | Foreign Desk | 129732 | 7.0% |
| 78 | 2.6% | Weekend Desk | 18814 | 1.0% |
| 74 | 2.5% | Leisure/Weekend Desk | 10766 | 0.6% |
| 72 | 2.4% | Long Island Weekly Desk | 20453 | 1.1% |
| 69 | 2.3% | Style Desk | 21569 | 1.2% |
| 57 | 1.9% | Financial Desk | 206958 | 11.2% |
| 44 | 1.5% | Arts & Leisure Desk | 6742 | 0.4% |
| 42 | 1.4% | The City Weekly Desk | 22863 | 1.2% |
| 41 | 1.4% | Connecticut Weekly Desk | 17034 | 0.9% |
Note: there are many errors in the specification of the desks … so this table should be digested with care.
authors
Extract the authors for the articles:
export PYTHONIOENCODING=utf-8
for year in $(seq 1987 2007); do
../nyt.py --author ../nyt_corpus_${year}.tar.gz \
| sed -e "s/^nyt_corpus_//" -e "s/\.har\//\//" -e "s/\.xml\t/\t/" \
| sort >> nyt_authors.tsv
done
Compute frequency distribution over all articles:
cut -d$'\t' -f2 nyt_authors.tsv | LC_ALL=C sort -S1G | uniq -c \
| sed -e "s/^ *//" -e "s/ /\t/" | awk -F'\t' '{print $2"\t"$1}' \
> nyt_authors_distrib.tsv
Check the number of and the top authors:
echo articles $(wc -l < nyt_authors.tsv)
echo categories $(wc -l < nyt_authors_distrib.tsv)
echo ""
sort -t$'\t' -nrk2 nyt_authors_distrib.tsv | head
| articles | 1854726 |
|---|---|
| categories | 30691 |
| 961052 | |
| Elliott, Stuart | 6296 |
| Holden, Stephen | 5098 |
| Chass, Murray | 4544 |
| Pareles, Jon | 4090 |
| Brozan, Nadine | 3741 |
| Fabricant, Florence | 3659 |
| Kozinn, Allan | 3654 |
| Curry, Jack | 3654 |
| Truscott, Alan | 3646 |
requires cleansing!
Collect the authors of the articles
echo "vossantos" $(../org.py -T README.org | wc -l) articles $(wc -l < nyt_authors.tsv)
../org.py -T -f fid README.org | join nyt_authors.tsv - | sed "s/ /\t/" | awk -F'\t' '{print $2}' \
| LC_ALL=C sort | uniq -c \
| sed -e "s/^ *//" -e "s/ /\t/" | awk -F'\t' '{print $2"\t"$1}' \
| LC_ALL=C join -t$'\t' -o1.2,1.1,2.2 - nyt_authors_distrib.tsv \
| sort -nr | head -n20
| vossantos | 3014 | author | articles | 1854726 |
|---|---|---|---|---|
| 470 | 15.6% | 961052 | 51.8% | |
| 34 | 1.1% | Maslin, Janet | 2874 | 0.2% |
| 32 | 1.1% | Holden, Stephen | 5098 | 0.3% |
| 30 | 1.0% | Vecsey, George | 2739 | 0.1% |
| 24 | 0.8% | Sandomir, Richard | 3140 | 0.2% |
| 24 | 0.8% | Dowd, Maureen | 1647 | 0.1% |
| 23 | 0.8% | Ketcham, Diane | 717 | 0.0% |
| 20 | 0.7% | Kisselgoff, Anna | 2661 | 0.1% |
| 20 | 0.7% | Brown, Patricia Leigh | 568 | 0.0% |
| 19 | 0.6% | Kimmelman, Michael | 1515 | 0.1% |
| 19 | 0.6% | Berkow, Ira | 1704 | 0.1% |
| 18 | 0.6% | Barron, James | 2188 | 0.1% |
| 17 | 0.6% | Stanley, Alessandra | 1437 | 0.1% |
| 17 | 0.6% | Pareles, Jon | 4090 | 0.2% |
| 17 | 0.6% | Lipsyte, Robert | 817 | 0.0% |
| 17 | 0.6% | Araton, Harvey | 1940 | 0.1% |
| 16 | 0.5% | Smith, Roberta | 2497 | 0.1% |
| 16 | 0.5% | Martin, Douglas | 1814 | 0.1% |
| 16 | 0.5% | Chass, Murray | 4544 | 0.2% |
| 15 | 0.5% | Grimes, William | 1368 | 0.1% |
Vossantos of the top author
# extract list of articles
for article in $(../org.py -T -f fid README.org | join nyt_authors.tsv - | grep "Maslin, Janet" | cut -d' ' -f1 ); do
grep "$article" README.org
done
- Bob Hope (1993/04/23/0604282) is loaded with rap-related cameos that work only if you recognize the players (Fab 5 Freddy, Kid Capri, Naughty by Nature and the Bob Hope of rap cinema, Ice-T), and have little intrinsic humor of their own.
- Sandy Dennis (1993/09/03/0632371) (Ms. Lewis, who has many similar mannerisms, may be fast becoming the Sandy Dennis of her generation.)
- Dorian Gray (1993/12/10/0654992) Also on hand is Aerosmith, the Dorian Gray of rock bands, to serve the same purpose Alice Cooper did in the first film.
- Adolf Hitler (1994/02/04/0666537) The terrors of the code, as overseen by Joseph Breen (who was nicknamed “the Hitler of Hollywood” in some quarters), went beyond the letter of the document and brought about a more generalized moral purge.
- Cinderella (1994/09/11/0711230) Kevin Smith, the Cinderella of this year's Sundance festival, shot this black-and-white movie in the New Jersey store where he himself worked.
- Hulk Hogan (1994/10/25/0720551) Libby's cousin Andrew, an art director who's “so incredibly creative that, as my mother says, no one's holding their breath for grandchildren,” opines that “David Mamet is the Hulk Hogan of the American theater and that his word processor should be tested for steroids.”
- Andrew Dice Clay (1995/09/22/0790066) Mr. Ezsterhas, the Andrew Dice Clay of screenwriting, bludgeons the audience with such tirelessly crude thoughts that when a group of chimps get loose in the showgirls' dressing room and all they do is defecate, the film enjoys a rare moment of good taste.
- Thomas Jefferson (1996/01/24/0825044) Last year's overnight sensation, Edward Burns of “The Brothers McMullen,” came out of nowhere and now has Jennifer Aniston acting in his new film and Robert Redford, the Thomas Jefferson of Sundance, helping as a creative consultant.
- Elliott Gould (1996/03/08/0835139) All coy grins and daffy mugging, Mr. Stiller plays the role as if aspiring to become the Elliott Gould of his generation.
- Charlie Parker (1996/08/09/0870295) But for all its admiration, ‘'Basquiat’' winds up no closer to that assessment than to the critic Robert Hughes's more jaundiced one: ‘'Far from being the Charlie Parker of SoHo (as his promoters claimed), he became its Jessica Savitch.’'
- Aesop (1996/08/09/0870300) Eric Rohmer's ‘'Rendezvous in Paris’' is an oasis of contemplative intelligence in the summer movie season, presenting three graceful and elegant parables with the moral agility that distinguishes Mr. Rohmer as the Aesop of amour.
- Diana Vreeland (1997/06/06/0934955) The complex aural and visual style of ‘'The Pillow Book’' involves rectangular insets that flash back to Sei Shonagon (a kind of Windows 995) and illustrate the imperious little lists that made her sound like the Diana Vreeland of 10th-century tastes.
- Peter Pan (1997/08/08/0949060) Mr. Gibson, delivering one of the hearty, dynamic star turns that have made him the Peter Pan of the blockbuster set, makes Jerry much more boyishly likable than he deserves to be.
- Thomas Edison (1997/09/19/0958685) Danny DeVito embodies this as a gleeful Sid Hudgens (a character whom Mr. Hanson has called '‘the Thomas Edison of tabloid journalism’’), who is the unscrupulous editor of a publication called Hush-Hush and winds up linked to many of the other characters’ nastiest transgressions.
- John Wayne (1997/09/26/0960422) Mr. Hopkins, whose creative collaboration with Bart goes back to ‘'Legends of the Fall,’' has called him '‘the John Wayne of bears.’'
- Annie Oakley (1997/12/24/0982708) Running nearly as long as ‘'Pulp Fiction’' even though its ambitions are more familiar and small, ‘'Jackie Brown’' has the makings of another, chattier ‘'Get Shorty’' with an added homage to Pam Grier, the Annie Oakley of 1970's blaxploitation.
- Robin Hood (1998/04/10/1008616) Do not threaten to call the police or have him thrown out,'' went a memorandum issued by another company, when the Robin Hood of corporate America went on the road to promote his book abou downsizing.
- Buster Keaton (1998/09/18/1047276) Fortunately, being the Buster Keaton of martial arts, he makes a doleful expression and comedic physical grace take the place of small talk.
- Michelangelo (1998/09/25/1049076) She goes to a plastic surgeon (Michael Lerner) who's been dubbed '‘the Michelangelo of Manhattan’' by Newsweek.
- Brian Wilson (1998/12/31/1073562) The enrapturing beauty and peculiar naivete of ‘'The Thin Red Line’' heightened the impression of Terrence Malick as the Brian Wilson of the film world.
- Dante Alighieri (1999/10/22/1147181) Though his latest film explores one more urban inferno and colorfully reaffirms Mr. Scorsese's role as the Dante of the Cinema, creating its air of nocturnal torment took some doing.
- Albert Einstein (2000/12/07/1253134) In this much coarser and more violent, action-heavy story, Mr. Deaver presents the villainous Dr. Aaron Matthews, whom a newspaper once called '‘the Einstein of therapists’' in the days before Hannibal Lecter became his main career influence.
- Émile Zola (2001/03/09/1276449) George P. Pelecanos arrives with the best possible recommendations from other crime writers (e.g., Elmore Leonard likes him), and with jacket copy praising him as '‘the Zola of Washington, D.C.’' But what he really displays here, in great abundance and to entertaining effect, is a Tarantino touch.
- Leonard Cohen (2002/08/22/1417676) The wry, sexy melancholy of his observations would be seductive enough in its own right – he is the Leonard Cohen of the spy genre – even without the sharp political acuity that accompanies it.
- Jane Austen (2002/10/07/1429887) Ms. Pearson does so well in capturing the funny, calculating aspects of her English heroine's life that The Guardian has called her '‘a Jane Austen among working mothers.’'
- Kato Kaelin (2003/04/07/1478881) Then he has settled in – as ‘'a permanent house guest, the Kato Kaelin of the wine country,’' in the case of Alan Deutschman – and tried to figure out what it all means.
- Hulk Hogan (2003/04/14/1480850) Meanwhile, at 5 feet 10 tall and 115 pounds, Andy is the Hulk Hogan of this food-phobic crowd.
- Nora Roberts (2003/04/17/1481531) For those who write like clockwork (i.e., Stuart Woods, the Nora Roberts of mystery best-sellerdom), a new book every few months is no surprise.
- Henny Youngman (2004/03/05/1563840) Together Mr. Yetnikoff and Mr. Ritz devise a kind of sitcom snappiness that turns Mr. Yetnikoff into the Henny Youngman of CBS.
- Frank Stallone (2004/09/20/1612886) He can read the biblical story of Aaron and imagine '‘the Frank Stallone of ancient Judaism.’'
- Marlon Brando (2005/11/08/1715899) He named his daughter Tuesday, after the actress Tuesday Weld, whom Sam Shepard once called '‘the Marlon Brando of women.’'
- Jesse James (2005/12/09/1723424) How else to explain ‘'Comma Sense,’' which has a blurb from Ms. Truss and claims that the apostrophe is the Jesse James of punctuation marks?
- Elton John (2006/12/11/1811150) Though Foujita had a fashion sense that made him look like the Elton John of Montparnasse (he favored earrings, bangs and show-stopping homemade costumes), and though he is seen here hand in hand with a male Japanese friend during their shared tunic-wearing phase, he is viewed by Ms. Birnbaum strictly as a lady-killer.
- Ernest Hemingway (2007/04/30/1844006) Mr. Browne also points out that when he introduced Mr. Zevon to an audience as '‘the Ernest Hemingway of the twelve-string guitar,’' Mr. Zevon said he was more like Charles Bronson.
modifiers
../org.py -T -f modifier,aId README.org \
| awk -F$'\t' '$1 != "" {print $1;}' \
| sort | uniq -c | sort -nr | head -n30
| count | modifier |
|---|---|
| 56 | his day |
| 34 | his time |
| 29 | Japan |
| 17 | China |
| 16 | tennis |
| 16 | his generation |
| 16 | baseball |
| 14 | her time |
| 13 | our time |
| 13 | her day |
| 12 | the Zulus |
| 11 | the 90's |
| 11 | the 1990's |
| 11 | politics |
| 11 | hockey |
| 10 | the art world |
| 10 | Brazil |
| 10 | basketball |
| 10 | ballet |
| 9 | jazz |
| 9 | fashion |
| 8 | today |
| 8 | Iran |
| 8 | his era |
| 8 | hip-hop |
| 8 | golf |
| 8 | football |
| 8 | dance |
| 7 | the 19th century |
| 7 | Mexico |
today
“today”
Who are the sources for the modifier “today”?
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "today" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 1 | Shoeless Joe Jackson |
| 1 | Buck Rogers |
| 1 | Bill McGowan |
| 1 | William F. Buckley Jr. |
| 1 | Ralph Fiennes |
| 1 | Julie London |
| 1 | Jimmy Osmond |
| 1 | Harry Cohn |
“his day”, “his time”, or “his generation”
Who are the sources for the modifiers “his day”, “his time”, and “his generation”?
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 ~ "his (day|time|generation)" {print $2;}' \
| sort | uniq -c | sort -nr | head
| count | source |
|---|---|
| 3 | Donald Trump |
| 2 | Mike Tyson |
| 2 | Pablo Picasso |
| 2 | Billy Martin |
| 2 | Dan Quayle |
| 2 | Arnold Schwarzenegger |
| 2 | Martha Stewart |
| 2 | L. Ron Hubbard |
| 2 | Tiger Woods |
“her day”, “her time”, or “her generation”
Who are the sources for the modifiers “her day”, “her time”, and “her generation”?
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 ~ "her (day|time|generation)" {print $2;}' \
| sort | uniq -c | sort -nr | head
| count | source |
|---|---|
| 4 | Madonna |
| 2 | Laurie Anderson |
| 1 | Hilary Swank |
| 1 | Pamela Anderson |
| 1 | Hillary Clinton |
| 1 | Lotte Lehmann |
| 1 | Oprah Winfrey |
| 1 | Marilyn Monroe |
| 1 | Coco Chanel |
| 1 | Judith Krantz |
country
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 ~ "(Japan|China|Brazil|Iran|Israel|Mexico|India|South Africa|Spain|South Korea|Russia|Poland|Pakistan)" {print $1;}' \
| sort | uniq -c | sort -nr | head
| count | country |
|---|---|
| 29 | Japan |
| 17 | China |
| 10 | Brazil |
| 8 | Iran |
| 7 | Mexico |
| 7 | Israel |
| 7 | India |
| 4 | South Africa |
| 4 | Poland |
| 3 | Spain |
What are the sources for the modifier … ?
“Japan”
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "Japan" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 5 | Walt Disney |
| 4 | Bill Gates |
| 2 | Nolan Ryan |
| 2 | Frank Sinatra |
| 1 | Richard Perle |
| 1 | Thomas Edison |
| 1 | Cal Ripken |
| 1 | Walter Johnson |
| 1 | Andy Warhol |
| 1 | Pablo Picasso |
| 1 | William Wyler |
| 1 | Stephen King |
| 1 | Brad Pitt |
| 1 | Richard Avedon |
| 1 | P. D. James |
| 1 | Rem Koolhaas |
| 1 | Steve Jobs |
| 1 | Ralph Nader |
| 1 | Madonna |
| 1 | Jack Kerouac |
“China”
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "China" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 4 | Barbara Walters |
| 2 | Jack Welch |
| 2 | Larry King |
| 1 | Louis XIV of France |
| 1 | Oskar Schindler |
| 1 | Napoleon |
| 1 | Keith Haring |
| 1 | Mikhail Gorbachev |
| 1 | Donald Trump |
| 1 | Ted Turner |
| 1 | Madonna |
| 1 | The Scarlet Pimpernel |
“Brazil”
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "Brazil" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 1 | Giuseppe Verdi |
| 1 | Jil Sander |
| 1 | Walter Reed |
| 1 | Lech Wałęsa |
| 1 | Jim Morrison |
| 1 | Bob Dylan |
| 1 | Elvis Presley |
| 1 | Scott Joplin |
| 1 | Larry Bird |
| 1 | Pablo Escobar |
sports
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 ~ "(baseball|hockey|basketball|tennis|golf|football|racing|soccer|sailing)" {print $1;}' \
| sort | uniq -c | sort -nr
| count | sports |
|---|---|
| 16 | tennis |
| 16 | baseball |
| 11 | hockey |
| 10 | basketball |
| 8 | golf |
| 8 | football |
| 6 | soccer |
| 6 | racing |
| 3 | women’s basketball |
| 3 | sailing |
| 3 | auto racing |
| 2 | pro football |
| 2 | New York baseball |
| 1 | Yale football fame |
| 1 | women’s hockey |
| 1 | women’s college soccer |
| 1 | this year’s national collegiate basketball tournament |
| 1 | the tennis tour |
| 1 | the tennis field |
| 1 | the soccer set |
| 1 | the racing world |
| 1 | the Olympic hockey tournament |
| 1 | stock-car racing |
| 1 | Rotisserie baseball |
| 1 | pro football owners |
| 1 | professional basketball coaches |
| 1 | professional basketball |
| 1 | motocross racing in the 1980’s |
| 1 | micro golfers |
| 1 | major league baseball |
| 1 | Laser sailing |
| 1 | Japanese baseball |
| 1 | Iraqi soccer |
| 1 | horse racing |
| 1 | hockey in the former Soviet Union |
| 1 | hockey commentary |
| 1 | high school baseball in New York |
| 1 | harness racing |
| 1 | golf criticism |
| 1 | football teams |
| 1 | football owners |
| 1 | football announcers |
| 1 | European hockey |
| 1 | country-club golf |
| 1 | college football underclassmen |
| 1 | college football these days |
| 1 | college football |
| 1 | college basketball |
| 1 | Chinese baseball |
| 1 | Brazilian basketball for the past 20 years |
| 1 | BMX racing |
| 1 | biddy basketball |
| 1 | basketball announcers |
| 1 | basketball analysts |
| 1 | basketball analysis |
| 1 | baseball’s new era |
| 1 | baseball managers |
| 1 | baseball executives |
| 1 | baseball collections |
| 1 | baseball cards |
Who are the sources for the modifier … ?
baseball
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "baseball" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 2 | P. T. Barnum |
| 2 | Larry Bird |
| 1 | Clifford Irving |
| 1 | Mike Tyson |
| 1 | Thomas Dooley |
| 1 | Marco Polo |
| 1 | Pablo Picasso |
| 1 | Horatio Alger |
| 1 | Rodney Dangerfield |
| 1 | Michael Jordan |
| 1 | Alan Alda |
| 1 | Brandon Tartikoff |
| 1 | Howard Hughes |
| 1 | Thomas Jefferson |
tennis
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "tennis" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 2 | George Foreman |
| 1 | Tim McCarver |
| 1 | Pete Rose |
| 1 | Nolan Ryan |
| 1 | Crash Davis |
| 1 | Spike Lee |
| 1 | John Madden |
| 1 | Michael Jordan |
| 1 | John Wayne |
| 1 | George Hamilton |
| 1 | Michael Dukakis |
| 1 | Jackie Robinson |
| 1 | Babe Ruth |
| 1 | Dennis Rodman |
| 1 | Madonna |
basketball
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "basketball" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 2 | Babe Ruth |
| 1 | Joseph Stalin |
| 1 | Martin Luther King, Jr. |
| 1 | Pol Pot |
| 1 | Johnny Appleseed |
| 1 | Adolf Hitler |
| 1 | Bugsy Siegel |
| 1 | Elvis Presley |
| 1 | Chuck Yeager |
football
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "football" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 1 | Ann Calvello |
| 1 | Michael Jordan |
| 1 | Bobby Fischer |
| 1 | Patrick Henry |
| 1 | Susan Lucci |
| 1 | Jackie Robinson |
| 1 | Babe Ruth |
| 1 | Rich Little |
racing
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "racing" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 2 | Rodney Dangerfield |
| 1 | John Madden |
| 1 | Bobo Holloman |
| 1 | Lou Gehrig |
| 1 | Wayne Gretzky |
golf
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 == "golf" {print $2;}' \
| sort | uniq -c | sort -nr
| count | source |
|---|---|
| 2 | Michael Jordan |
| 2 | Jackie Robinson |
| 1 | J. D. Salinger |
| 1 | James Brown |
| 1 | Marlon Brando |
| 1 | Babe Ruth |
culture
../org.py -T -f modifier,sourceUrl README.org \
| awk -F$'\t' '$1 ~ "(dance|hip-hop|jazz|fashion|weaving|ballet|the art world|wine|salsa|juggling|tango)" {print $1;}' \
| sort | uniq -c | sort -nr | head -n13
| count | modifier |
|---|---|
| 10 | the art world |
| 10 | ballet |
| 9 | jazz |
| 9 | fashion |
| 8 | hip-hop |
| 8 | dance |
| 4 | wine |
| 4 | salsa |
| 2 | the hip-hop world |
| 2 | the fashion world |
| 2 | the fashion industry |
| 2 | the dance world |
| 2 | juggling |
Michael Jordan
../org.py -T -f sourceLabel,modifier README.org \
| awk -F$'\t' '{if ($1 == "Michael Jordan") print $2}' \
| sort -u
the Michael Jordan of
- …
- 12th men
- actresses
- Afghanistan
- Australia
- baseball
- BMX racing
- boxing
- Brazilian basketball for the past 20 years
- bull riding
- college coaches
- computer games
- cricket
- cyberspace
- dance
- diving
- dressage horses
- fast food
- figure skating
- foosball
- football
- game shows
- geopolitics
- golf
- Harlem
- her time
- his day
- his sport
- his team
- his time
- hockey
- horse racing
- hunting and fishing
- Indiana
- integrating insurance and health care
- julienne
- jumpers
- language
- Laser sailing
- late-night TV
- management in Digital
- Mexico
- motocross racing in the 1980's
- orange juice
- real-life bulls
- recording
- Sauternes
- snowboarding
- soccer
- television puppets
- tennis
- the Buffalo team
- the dirt set
- the Eagles
- the game
- the Hudson
- the National Football League
- the South Korean penal system
- the sport
- the White Sox
- this sport
- women's ball
- women's basketball